Note
Before starting configuration, a new module instance must be created. Click here for more information about creating Module instances.
Agent
Agent configuration defines the settings for importing files. The following screenshot shows the different available options for Agent configuration:
.png)
.png)
Parameters:
The Enable parameter enables or disables the Data Importer agent.
The Scan Rate specifies the check rate for the input folder, displayed in milliseconds. The minimum value is 100ms.
The Path parameter specifies the input directory where files are located. This path can either be a relative path, in which case it will be relative to the data folder of this Data Importer instance, or an absolute path.
The Parser specifies the parser used to parse the contents of the imported files.
File Management
The File Management menu contains the following settings:
The Loaded Path setting specifies the destination directory for files that have been imported correctly. This path can either be a relative path, in which case it will be relative to the Loaded folder (existing within the data folder of this Data Importer instance), or an absolute path.
The Maximum Loaded Files setting specifies the maximum number of loaded files to store in the loaded folder (existing within the data folder of this Data Importer instance). Set to 0 to immediately delete loaded files.
The Failed Path parameter specifies the destination directory for files that could not be imported correctly. This path can either be a relative path, in which case it will be relative to the Failed folder (existing within the data folder of this Data Importer instance), or an absolute path.
The Maximum Failed Files setting specifies the maximum number of failed files to store in the loaded directory (existing within the data folder of this Data Importer instance). Set to 0 to immediately delete loaded files.
Parser
The Parser is used to configure the parser in order to properly parse files for import. This menu contains the following settings:
The Separator setting specifies the column separator used in the CSV file.
The Comment Character setting specifies the character to be used for comments in the CSV file. Any lines beginning with this character are ignored by the parser.
The Row Skip setting specifies how many lines the parser will skip from the beginning of the file, not counting blank lines. This can be used to skip the first line (or lines) containing metadata or the header. Set to 0 to disable it and parse the CSV from the first line.
The Mode setting specifies how data is interpreted from the CSV file.
Time Stamp settings:
The Timezone setting specifies the time zone used to parse the data timestamp in the CSV file. The available options are:
UTC: Timestamp will use the UTC timezone or GMT.
Server: Timestamp will use the timezone of the server where the module is located.
Custom: Timestamp will use the timezone specified in “Custom Timezone”.
The Custom Timezone parameter specifies the desired timezone format when the Timezone setting is set to “custom”.
The Format setting specifies how the timestamp will be parsed. The following options are available:
Auto-detect: attempts to parse the timestamp using several standard formats, such as ISO 8601 or RFC 2822. If the format can’t be parsed, the corresponding tag will be set to bad quality.
Custom Format: uses a format string to parse the timestamp. If the parser fails, the corresponding tag will be set to bad quality.
The Format String setting specifies the format of the timestamp string used when the format setting is set to Custom.
Columns:
The Tag parameter specifies the index of the column containing the tag path. The minimum value is 1, which refers to the first column of the CSV.
The Value setting specifies the index of the column containing the tag value. The minimum value is 1, which refers to the first column of the CSV.
The Quality setting specifies the index of the column containing the tag quality. This value can be set to 0 (or Disabled), which means that the CSV file does not contain a value for the tag quality and all values will be imported with a quality of 192 (Good). Otherwise, it can be set to any value higher than 0.
The Timestamp setting specifies the index of the column containing the timestamp. This value can be set to 0 (or Disabled), which means that the CSV file does not contain a timestamp for the different values. This will prompt Data Importer to import all values with the current date and time as their timestamp. Otherwise, it can be set to any value higher than 0.
Files Filter
The Files Filter contains the following settings:
The Pattern setting specifies the regular expression used to filter which files from the directory are parsed with the Data Importer agent. If left empty, any filename will match the filter.
The Ignore Flag setting specifies the ignore case flag for the regular expression.
Tag configuration
Agent configuration defines the settings used for importing files. After configuring the Agent, users will be able to create and configure any Tags associated to the data received from imported files, as seen in the following example:
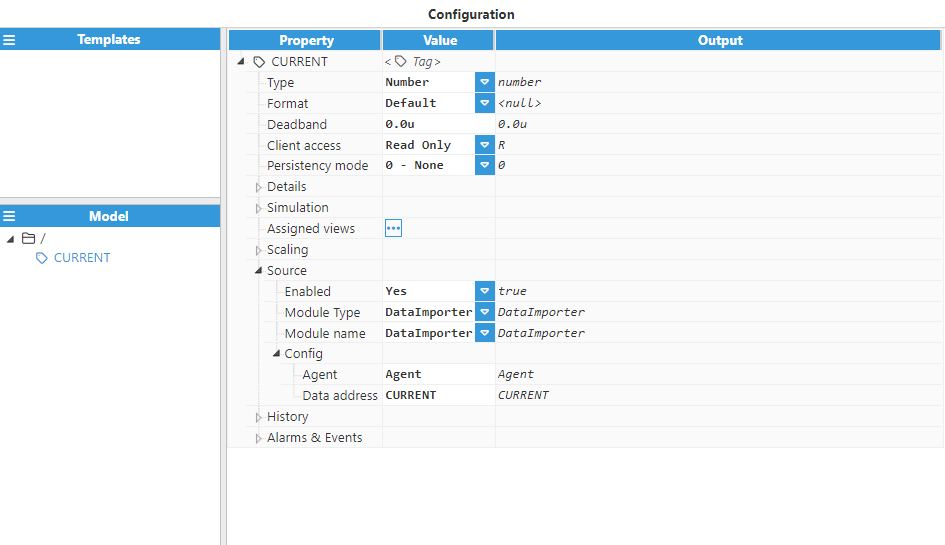
Source contains the following settings:
The Enabled setting enables reading of tags from their source.
The Module Type parameter specifies the source module type that will be used to read the tag.
The Module Name parameter specifies the source module name that will be used to read the tag.
Config contains the following settings:
The Agent setting specifies the agent used to provide values to this tag.
The Data Address parameter specifies the address of the data for this tag. For CSV parsers, this option is used to specify the name of this tag within the CSV file.