User defined scripts are used mainly in the following three cases:
To serialize tag events into a Dataset ready to be inserted into the database.
To create the query for exchanging, extracting, or sending data to the database.
To parse a Dataset obtained from the database into data objects, ready to write or update the tags.
These scripts use the JavaScript language, and have access to the standard JavaScript functions and objects (such as parseInt or the Date object), as well as the following additional libraries and functions added by the N3uron platform.
Moment
Moment is a JavaScript library that simplifies date parsing and formatting, as well as manipulating dates (such as adding a specific duration to a date). The SQL Client version also includes Moment Timezone, which is used to parse dates in specific time zones and to change time zones that are given a moment object.
Moment can be accessed by directly invoking the moment() constructor, while Moment Timezone is accessed using moment.tz()
Documentation about Moment can be found in Moment.js and Moment Timezone.
Buffer
Buffer is a Node.js class that is used to create and manipulate binary arrays. This class is used whenever a field needs to be a binary value, or when converting between different encodings (for example, from Base64 to UTF-8). Documentation about the Buffer class can be found at Node.js Buffer API.
sprintf
Sprintf is a function used to format any string that is given a format pattern containing placeholders or several variables that will substitute the placeholders. The format is similar to C's sprintf, as it supports placeholders using the special character %. The following examples are valid placeholders for different data types:
Integer: %d or %i
String: %s
Binary: %b
Boolean: %t
JSON: %j
ASCII character in decimal: %c
Scientific notation: %e
Floating point: %f
Fixed point: %g
Octal: %o
Unsigned integer: %u
Hexadecimal lowercase: %x
Hexadecimal uppercase: %X
Node buffer: %r
If the integer and the unsigned integer format type receive a decimal number, they truncate the decimal part.
All formats that admit decimal numbers, such as floating point or scientific notation, can be configured to specify the required number of decimals to display by using the format %.xY, where x is the number of decimals, and Y is the format used (f, for floating point; e, for exponential, etc). For example, to show a floating-point number with 2 decimals, the following format must be used: %.2f.
See below for examples of the different format options in the following script:
$.sprintf(“Numbers are: %d and %i”, 10, 15.7)
//Numbers are: 10 and 15
$.sprintf(“String is: %s”, “Hello world!”);
//String is: Hello world!
$.sprintf(“The binary representation of 5 is: %b”, 5);
// The binary representation of 5 is: 101
$.sprintf(“The ASCII character with decimal value 48 is %c”, 48);
// The ASCII character with decimal value 48 is 0
$.sprintf(“1000 in scientific notation is: %e”, 1000);
1000 in scientific notation is: 1e3
$.sprintf(“1234 in scientific notation and 2 decimals is: %.2e”, 1234);
//1234 in scientific notation and 2 decimals is: 1.23e3
$.sprintf(“12.34 in floating point notation is: %f”, 12.34)
//12.34 in floating point notation is: 12.34
$.sprintf(“12.3456 in fixed point notation is: %.3g”, 12.3456);
//12.3456 in fixed point notation is: 12.3
$.sprintf(“12 in octal is: %o”, 12);
//12 in octal is: 14
$.sprintf(“-10 in unsigned integer format is: %u”, -10)
//-10 in unsigned integer format is: 4294967286
$.sprintf(“30 in hexadecimal is: %x”, 30);
//10 in hexadecimal is: 1e
$.sprintf(“30 in uppercase hexadecimal is: %X”, 30);
//30 in uppercase hexadecimal is: 1E
var buf = new Buffer([“Hello world!”]);
$.sprintf(“The buffer is: %r”, buf);
//The buffer is: <48 65 6c 6c 6f 20 77 6f 72 6c 64 21>;
$.logger
The $.logger object is used to log messages to the disk, which can be used for both debugging and informative purposes. The log file can be found at N3uron/log/SqlClientInstaceName/. It’s shared by both the internal execution of the module and the messages written by the users. The logger has five different logging levels:
$.logger.error()
$.logger.warn()
$.logger.info()
$.logger.debug()
$.logger.trace()
Each of the logging functions have two arguments:
(String) message: Format string using sprintf formatting.
(Any) arguments: Arguments that will replace the placeholders in the format string.
$.parameter
Transactions with parameters can be used by accessing the $.parameter object.
Each parameter corresponds to one or more tag events, and each tag event includes the following properties:
value: The current value of the tag (number, string, boolean, or null).
quality: The parameter quality is a number in the range of 0-255, which represents a level of confidence in the tag value.
ts (timestamp): The parameter timestamp is a number that represents the number of milliseconds lapsed since January 1970 (Unix Epoch).
initial: A boolean value indicating whether this is an initial value of the tag. It is typically true when there is a restart or re-subscription in the source module for this tag (for example: Modbus, MQTT, OPC UA, etc.).
There are three types of Parameters:
Single tag: This parameter will contain a single tag specified with a tag path.
Tag group: This parameter will contain a group of tags that are included in the specified path.
Multiple tags (Filter): This parameter will contain any of the tags that match the given filters.
As an example, consider a Wind Turbine tag model with tags from: WT-1001, WT-1002 and WT-1003.
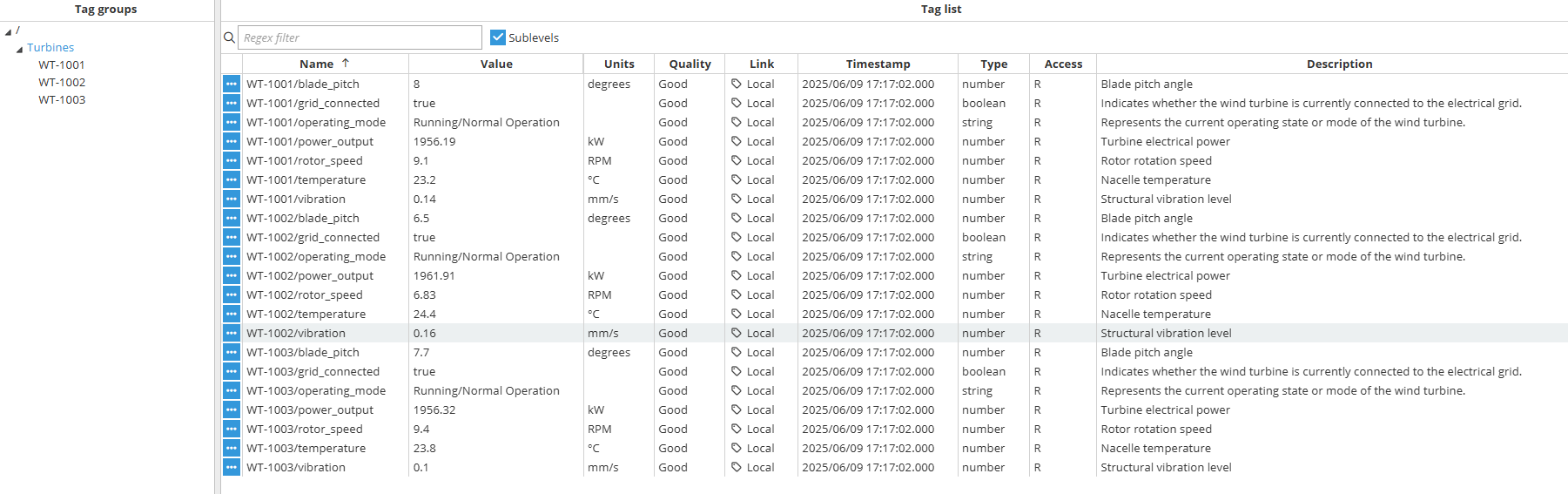
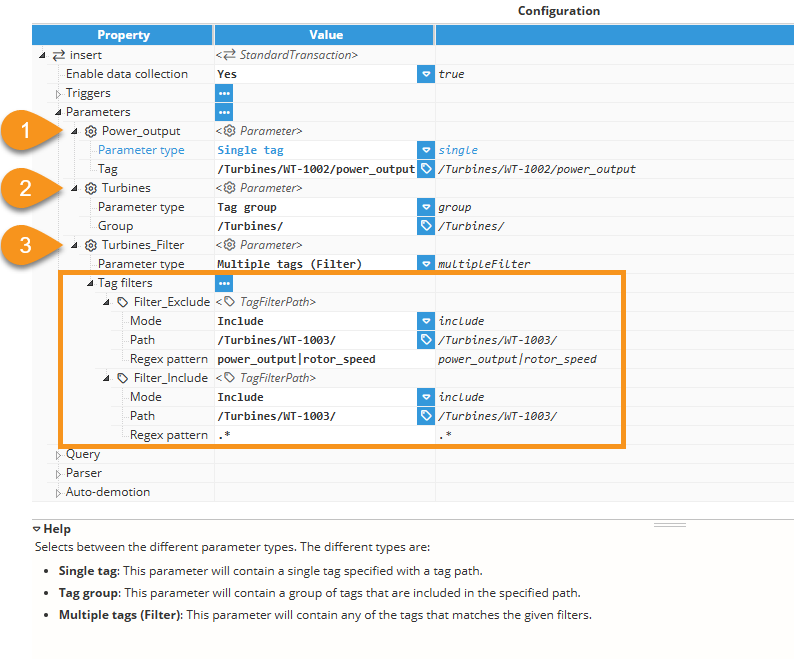
The image shown above illustrates an example of a Transaction Parameters configuration. It demonstrates how to configure and use the three available parameter types.
If a parameter is configured to reference the Wind Turbine tags, as shown in the example, its values can be accessed in your script through the $.parameter object. The last known value of any parameter can be accessed using one of the following forms:
$.parameter['paramName'].value
$.parameter.paramName.value
Where paramName refers to the name of the parameter instance defined in the transaction configuration. For example: $.parameter.Power_output.value or $.parameter.Turbines.value. The same applies for ts (timestamp) or quality attributes: $.parameter.Power_output.ts or $.parameter.Power_output.quality.
Power_output parameter.
Parameter type: Single tag.
Tag: /Turbines/WT-1002/power_output.
$.parameter.Power_output references a specific tag and will return a single tag object.
{ "tag": "/Turbines/WT-1002/power_output", "value": 1958.39, "quality": 192, "ts": 1749483005000, "initial": false }
Turbines parameter.
Parameter type: Tag group.
Group: /Turbines/.
$.parameter.Turbines references a group of tags under the specified group path and returns an array of tag objects.
[ { "tag": "/Turbines/WT-1001/power_output", "value": 1961.82, "quality": 192, "ts": 1749483005000, "initial": false }, { "tag": "/Turbines/WT-1001/rotor_speed", "value": 14.67, "quality": 192, "ts": 1749483005000, "initial": false }, ... ]
Turbines_Filter parameter
Parameter type: Multiple tags (Filter).
Tag Filters:
Filter_Exclude.
Mode: Exclude.
Path: /Turbines/WT-1003/.
Regex pattern: power_output|rotor_speed.
Filter_Include.
Mode: Include.
Path: /Turbines/WT-1003/.
Regex pattern: .*.
$.parameter.Turbines_Filter, is configured to include all tags under /Turbines/WT-1003/, except for power_output and rotor_speed. This allows you to filter out specific tags when retrieving the tag group selectively, and returns an array of tag objects.
[ { "tag": "/Turbines/WT-1003/blade_pitch", "value": 6.6, "quality": 192, "ts": 1749483005000, "initial": false }, { "tag": "/Turbines/WT-1003/temperature", "value": 24.6, "quality": 192, "ts": 1749483005000, "initial": false }, { "tag": "/Turbines/WT-1003/vibration", "value": 0.1, "quality": 192, "ts": 1749483005000, "initial": false }, { "tag": "/Turbines/WT-1003/operating_mode", "value": "Running/Normal Operation", "quality": 192, "ts": 1749483005000, "initial": false }, { "tag": "/Turbines/WT-1003/grid_connected", "value": true, "quality": 192, "ts": 1749483005000, "initial": false } ]
Since $.parameter is a JavaScript object, it can be iterated to programmatically obtain all parameters using the for…of syntax. An iteration example can be seen in the following snippet:
for (const [param, value] of Object.entries($.parameter)){
$.logger.info("Parameter %s is %j", param, value);
}Extract Tag Objects as a Flat Array from Parameters:
This sample function demonstrates how to extract and flatten all values from Parameters into a single array. It supports both cases where a parameter value is an array of tag objects (each element will be added individually) or a single tag object (added directly). The result is a flat array of parameter values, which can then be used for further processing.
function getValuesFromParameters() {
const parameterValues = [];
for (const paramValue of Object.values($.parameter)) {
if (Array.isArray(paramValue)) {
// Parameter is an array: append each element individually
for (const element of paramValue) {
parameterValues.push(element);
}
} else {
// Parameter is a single tag object: append it directly
parameterValues.push(paramValue);
}
}
return parameterValues;
}
$.local
$.local is an empty object that can be used to store any user variables that persist between transaction executions, as well as any variables that are shared between different scripts belonging to the same transaction. For example, when creating a local variable named "count", the following syntax is used:
//Only define the variable if it's undefined
if($.local.count === undefined) $.local.count = 0;Understanding $.input and $.output objects in Standard and History transaction scripts
The data accessible to, and generated by, custom scripts in Standard and History transactions depends on the script’s function within the transaction process. The following summarizes how the $.input and $.output objects behave for each script type, clarifying what data is available for use and what can be produced for downstream processing.
Standard transaction
.png)
Script Type | $.input Value/Type | $.output Value/Type | Description |
|---|---|---|---|
Custom Query | null | String (SQL query) |
|
Custom Parser | Dataset or array of Datasets (from DB query result) | Array of Tag data objects |
|
1) Custom Query Script:
$.input: Null.
Use $.parameter to access input values from tags for dynamic SQL queries (e.g., INSERT, UPDATE).
$.output: Must be a string containing the SQL query to be executed by the database. If an incorrect type is used, an exception will be logged and the transaction will be aborted.
2) Custom Parser Script:
$.input: Contains the results returned by the database:
A single Dataset for one result set (e.g., a single SELECT query).
An array of Datasets for multiple result sets (e.g., multiple SELECT queries).
$.output: Must be an array of Tag data objects, at the very minimum, one tag property and one value property and can also contain a quality and a timestamp (displayed in UNIX Epoch format with milliseconds). If an incorrect output type is used, an exception will be logged and the transaction will be aborted.
History transaction
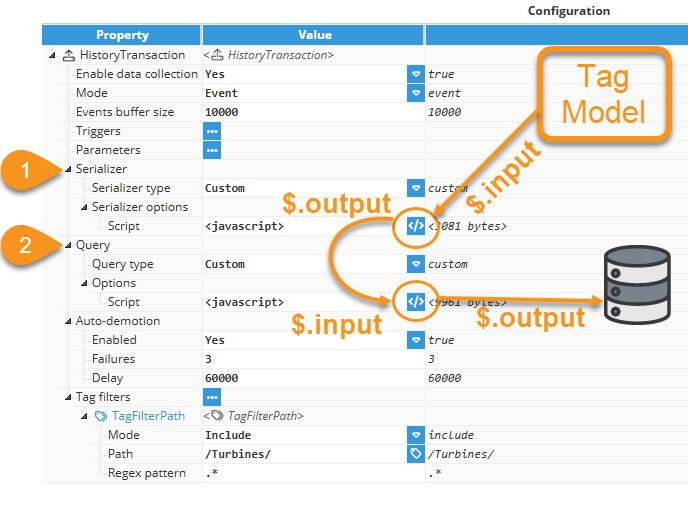
Script Type | $.input Value/Type | $.output Value/Type | Description |
Custom Serializer | Array of tag data objects | Dataset or array of Datasets |
|
Custom Query | Dataset or array of Datasets (from the Custom Serializer) | String (SQL query) |
|
1) Custom Serializer Script:
$.input: Contains an array of Tag data objects, as filtered by the Tag Filter. Each object includes tag, value, quality, and timestamp properties.
$.output: Must be a Dataset or an array of Datasets suitable for the Custom Query script. The Dataset contains the serialized Tag data objects. If an incorrect output type is used, an exception will be logged and the transaction will be aborted.
2) Custom Query Script:
$.input: Receives the Dataset or array of Datasets produced by the Custom Serializer script.
$.output: Must be a string containing the SQL query to be executed by the database. If an incorrect output type is used, an exception will be logged and the transaction will be aborted.
Dataset
The Dataset class is a representation of a database table in SQL Client. As such, it has columns that correspond to the database columns, with a name and a type, and rows that contain data for these columns.
A Dataset instance is also an iterator, which means that it can be used implicitly with a for…of loop to iterate through all rows in the Dataset. The method’s rows and columns can also be used to obtain an iterator over the rows and columns explicitly.
Since the Dataset columns have a type, the Dataset will declare the following enumeration, which contains all available types:
Dataset.Types:
CHAR
VARCHAR
NCHAR
NVARCHAR
BINARY
VARBINARY
NUMERIC
DECIMAL
SMALLINT
INT
BIGINT
FLOAT
REAL
DOUBLE
BOOLEAN
DATE
TIME
TIMESTAMP
DATETIME
JSON
TEXT
TINY_INT
YEAR
ENUM
TINY_BLOB
BLOB
MEDIUM_BLOB
LONG_BLOB
TEXT
MEDIUM_INT
SET
Datasets have the following methods:
Dataset()
The constructor of the Dataset class takes no parameters and is used to create a new empty Dataset.getColumnCount(): number
Returns the number of columns included in the Dataset.getColumnIndex(colName: string): number
Returns the numeric index of the column as per the specified name. If the column is not present in the Dataset, it returns -1.getColumnName(index: number): string
Returns the name of the column for the specified index. If the index is negative or higher than the number of columns, an exception is thrown.getColumnNames(): string[]
Returns an array of column names for all columns present in the Dataset.getColumn(col: string | number): DatasetColumn
Returns the column with the specified name (if col is a string) or the column at the specified index (if col is a number). If the column doesn't exist, the value “undefined” is returned.getRowCount(): number
Returns the total number of rows present in the Dataset.getRow(row: number): DatasetRow
Returns the row number at the specified index (or undefined if the index is out of bounds).getValue(row: number, column: number | string): any
Returns present at the given row and column. Column can either be a column name or an index. If either the row or column is out of range, an exception is thrown.setValue(row: number, column: number | string, value: any): void
Sets the value at the specified row and column. The Column can either be a name or an index. If either the row or the column is out of range, an exception is thrown. The value will be automatically cast to the column type, if possible.addColumn(name: string, type: Dataset. Type | string): void
Adds a new column to the Dataset, as per the specified name and type. If the Dataset contains any rows, the new column will be assigned a null value by default for all rows.addRow(data: any[] | object): void
Adds a new row to the Dataset with the specified data. The data can be either an array of values or an object, where each key corresponds to a column. If there are not enough fields to completely fill the row, an exception will be thrown.rows(): Iterator<DatasetRow>
Returns an iterator over the rows of the Dataset, which can be used in for…of loops.columns(): Iterator<DatasetColumn>
Returns an iterator over the columns of the Dataset, which can be used in for…of loops.getRows(): DatasetRow[]
Returns an array that comprises all rows present in the Dataset.getColumns(): DatasetColumn[]
Returns an array comprised of all columns present in the Dataset.
DatasetRow
This class represents a row from the Dataset. Each row in a given Dataset has the same number of columns. DatasetRow objects are not manually created by the user as they are created automatically by invoking the addRow method of a particular Dataset. DatasetRows can be used implicitly as an iterator in a for…of loop, which will iterate over the fields of the row. It also has an explicit method (fields) that will return the same iterator.
Each DatasetRow has the following methods:
getFieldCount(): number
Returns the number of fields present in this row.getValue(column: string | number): any
Returns the value of the field with the specified column name (if column is a string) or the column index (if it's a number). If the column doesn't exist, an exception is thrown.setValue(column: string | number): any
Sets the value of the field with the specified column name (if column is a string) or the column index (if it's a number). If the column doesn't exist, an exception is thrown. The value passed as the parameter is cast to the column type (if possible) or set to null if the cast is not possible.fields(): IterableIterator<any>
Returns an iterator over the fields of this row that can be used in for…of loops.
DatasetColumn
This class represents a column in the Dataset. Each column has a name and a type, which means that whenever a value is inserted in a row of a given column, it will attempt to cast it to the appropriate type, or null if the cast is invalid.
DatasetColumns cannot be implicitly created by a user. Instead, the addColumn method for a Dataset has to be used to create a new column. Each DatasetColumn has the following methods:
getName(): string
Returns the name of this column.getType(): string
Returns the column type as a string.
Database value types
When a query returns data, it will automatically be converted to a Dataset. The Dataset column types are based on the same types as those that apply to the columns of the database. However, as JavaScript only has a limited number of primitive types, the value type itself must be one of the following types, depending on the column type:
String:
CHAR, VARCHAR, NCHAR, NVARCHAR, TEXT, ENUM, SET and JSON are cast to a string directly.
TIME will be cast to a string, since it conveys no date information and as such, cannot be unambiguously cast to a Date. If a Date object is desired, it can be created by using moment and a custom format string. For example, moment(TIME_STRING, "hh:mm:ss.SSS").
BIGINT, NUMERIC and DECIMAL can potentially offer more precision than the number type in JavaScript. As such, by default, they are cast to a string. If a number is desired, the parseInt or parseFloat method can be used to parse the string (with potential loss of precision).
Any other types that are not handled by the Dataset will also be attempted to be cast to a string as a fallback.
Buffer:
BINARY, VARBINARY, TINY_BLOB, BLOB, MEDIUM_BLOB and LONG_BLOB are cast to a Buffer instance. As such, any of the Buffer methods can be used to read and manipulate the Buffer data.
Number:
FLOAT, REAL, DOUBLE, SMALLINT, INT, TINY_INT, MEDIUM_INT are cast to Number directly.
YEAR is cast to Number, since a YEAR cannot be unambiguously cast to a Date object. If a Date object is desired, YEAR can be explicitly cast to one by using moment and a custom format string, such as moment(YEAR_NUMBER, "YYYY").
Date:
DATE, TIMESTAMP and DATETIME are cast to a JavaScript Date object. This can be used directly, or alternatively, a moment object can be created by invoking the moment function with the Date value (moment(DATE_OBJECT)).
Boolean:
BOOLEAN is cast directly to the Boolean JavaScript type.
Value casting
When a new value is added to a Dataset from a script, it will be cast to the appropriate type depending on the column type. The following casting rules are used for the different available types:
String: CHAR, VARCHAR; NCHAR, NVARCHAR, TIME, ENUM, BIGINT, TEXT, NUMERIC, DECIMAL, SET and JSON will be cast to a string:
Casting to strings is done by invoking the toString method. If this method is not available, the value will be cast to null.
JSON is a special case of string casting. When the value passed is a string, it will be left as is (which can result in errors down the line if the string is not a valid JSON. As such, the string must always be a valid JSON). If the value passed is not a string, it will be cast to a JSON string using JSON.stringify function.
Buffer: BINARY, VARBINARY, TINY_BLOB, BLOB, MEDIUM_BLOB and LONG_BLOB will be cast to a Buffer object.
If the value is a Buffer, the value will be inserted without any changes.
If the value is a number, a new Buffer with size 8 will be created and the number will be stored as a 64-bit Double with big-endian byte ordering.
If the value is a Boolean, a new Buffer with size 1 will be created, and the Boolean value will be stored as an 8-bit unsigned integer.
If the value is a string, a new Buffer with the same size as the string is created, and the string is stored as a UTF-8 encoded string.
Number: FLOAT, REAL, DOUBLE, SMALLINT, INT, TINY_INT, MEDIUM_INT and YEAR will be cast to a JavaScript number.
If the value can't be parsed to a number correctly (resulting in a NaN value), null will be inserted.
If the value is a string, it will be parsed into a number, either with parseFloat (FLOAT, REAL and DOUBLE) or with parseInt (all other types).
Date: DATE, TIMESTAMP and DATETIME will be cast to a JavaScript Date object.
The values are parsed using the Date constructor. If the date is not valid, null will be inserted.
Boolean: BOOLEAN will be cast to a Boolean value.
If the type is a string, "true", "y" and "t" will be cast to true, and everything else to false.
If the type is anything else, it will be cast to Boolean directly, which means that 0, null, undefined, and empty strings are false, and everything else is true.
Null:
If any of the cast fails, the value inserted is null.
If the value passed to the Dataset is null, undefined, an array, a symbol, or a function, it will be cast as null.
Tag data object
Whenever data is saved from a database to N3uron, the data must be parsed into a format that is compatible with N3uron tags, which can be an array of tag data objects. The format of a tag data object differs slightly when the data is saved to a source tag, as opposed to when it is written to a tag. The tag data formats are as follows:
TAG_ADDRESS: This value is used to associate the given tag event with a tag within the N3uron tag model. The value can be either a tag path or a tag address, or even an alias (if an alias is defined in the tag configuration).
TAG_VALUE: This is the value that will be saved to the specified tag. It can be a number, a string, or a Boolean value and if the destination tag has a different type, casting to the correct type will be attempted.
TAG_QUALITY: This property is set to optional when the tag is an SqlClient source tag, or set as a non-obligatory field if dealing with a tag write operation (another driver controls the tag). If defined, this field specifies the quality of this tag event. The property type is a number between 0 and 255. Qualities with values in the 0-64 interval are considered bad, 64-127 are uncertain, and values between 192 and 255 are good. If this value is omitted when acting as the source, it will be automatically set to 192 (GOOD_NON_SPECIFIC).
TAG_TIMESTAMP: This property is set to optional when the tag is an SqlClient source tag, and set as a non-obligatory field if dealing with a tag write operation (another driver controls the tag). If defined, this field sets the timestamp of this tag event. The property type is a number, and the value must be the number of milliseconds lapsed since 1970 (displayed in UNIX Epoch). For easy parsing of dates, Date and/or moment is recommended. If this value is omitted when acting as a source, the timestamp will be automatically set to the current time (using the Date.now()function).
{
tag: TAG_ADDRESS,
value: TAG_VALUE,
quality: TAG_QUALITY,
ts: TAG_TIMESTAMP
}